Resilient and Cost-Optimized Artifactory Hosting on AWS
TL;DR
The Artifactory setup described in this article should allow you to save a good amount on your AWS bill. In fact, we succeeded building a new setup that is much cheaper than our previous one, going from a couple of thousand dollars to only a couple of hundred.
Already read enough? Feel free to jump into the infrastructure code to set things up right away 😉 Artifactory Migration Steps
Scenario
We recently had to migrate and upgrade Artifactory on AWS. The existing Artifactory was installed on AWS years ago when its ecosystem was still much smaller. A lot has changed in the meantime, making the setup outdated and no longer cost-efficient.
Our task was optimizing the setup to reduce cost and improve Recovery Time Objective (RTO) and Recovery Point Objective (RPO)
The legacy setup
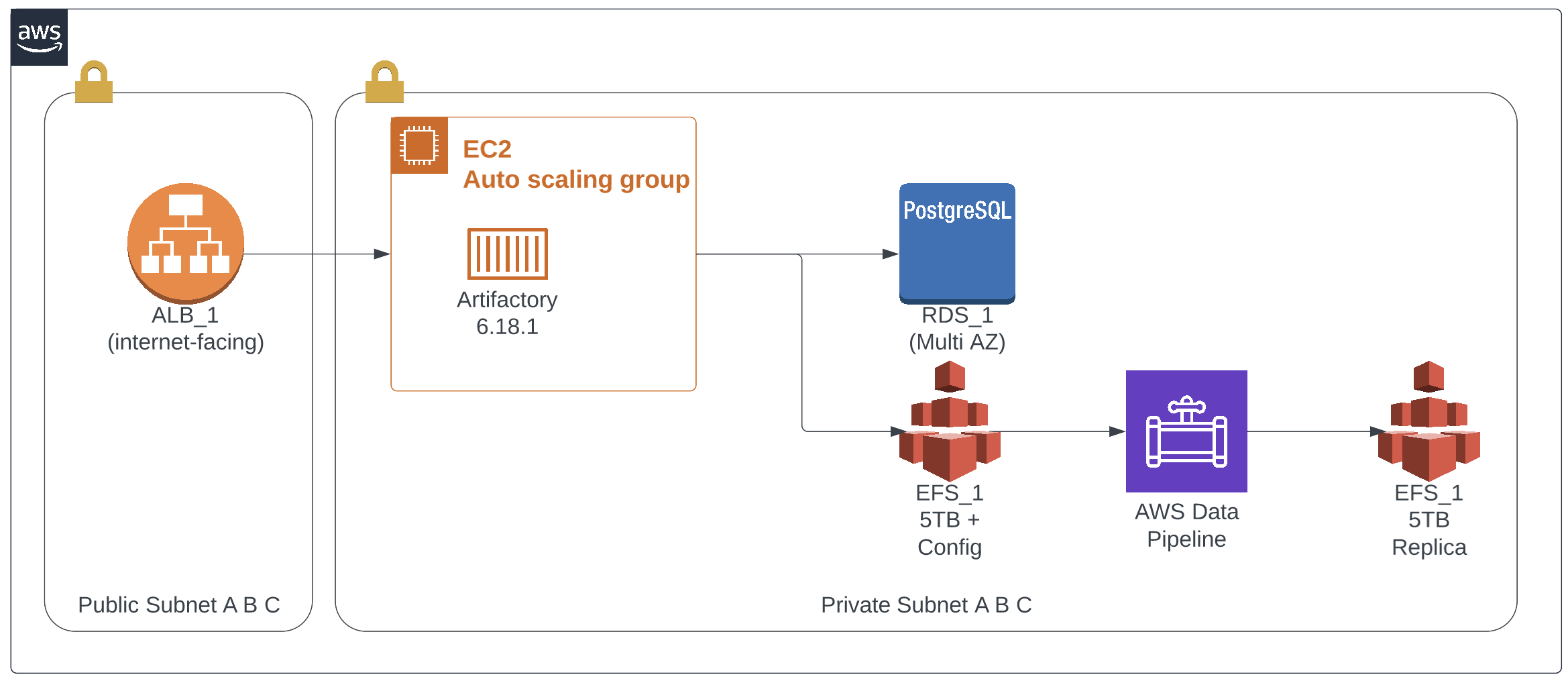
The legacy environment was deployed using CloudFormation without a CI/CD pipeline.
The stack contained an EC2 auto-scaling group used to spin up a single t2.medium instance. All EC2 config was done using cfn-init.
EFS was used to store the Artifactory config files and artifacts. In this setup, Artifactory had a few hundred thousand artifacts with a total size of multiple Terrabytes and was growing steadily. All files were stored using the standard storage class. There were no lifecycle rules, so no files were moved to Infrequent access. As a result, the cost of EFS was skyrocketing.
At the initial setup time, EFS had no option for replication. Also AWS Backup was unavailable back then. For resiliency, AWS Data pipeline was used to sync the EFS to another EFS.
Preliminary Optimizations
The Data Pipeline replication solution was brittle, the sync happened only once a day, and the replica was located in the same region and availability zone. Having both volumes in the same region meant both would fail in case of a regional outage. An EFS multi-AZ configuration partially mitigates the problem but would not help if EFS fails simultaneously in all availability zones.
On top, replication doesn’t protect against data corruption, it will just replicate corrupt data. Looking at it, replication is quite costly and doesn’t add much value. Therefore it will be removed.
Another cost-optimization was enabling Infrequent Access on EFS. In our case, more than 99% of the artifacts transitioned to the IA storage class after seven days, resulting in a big cost reduction.
The new Setup
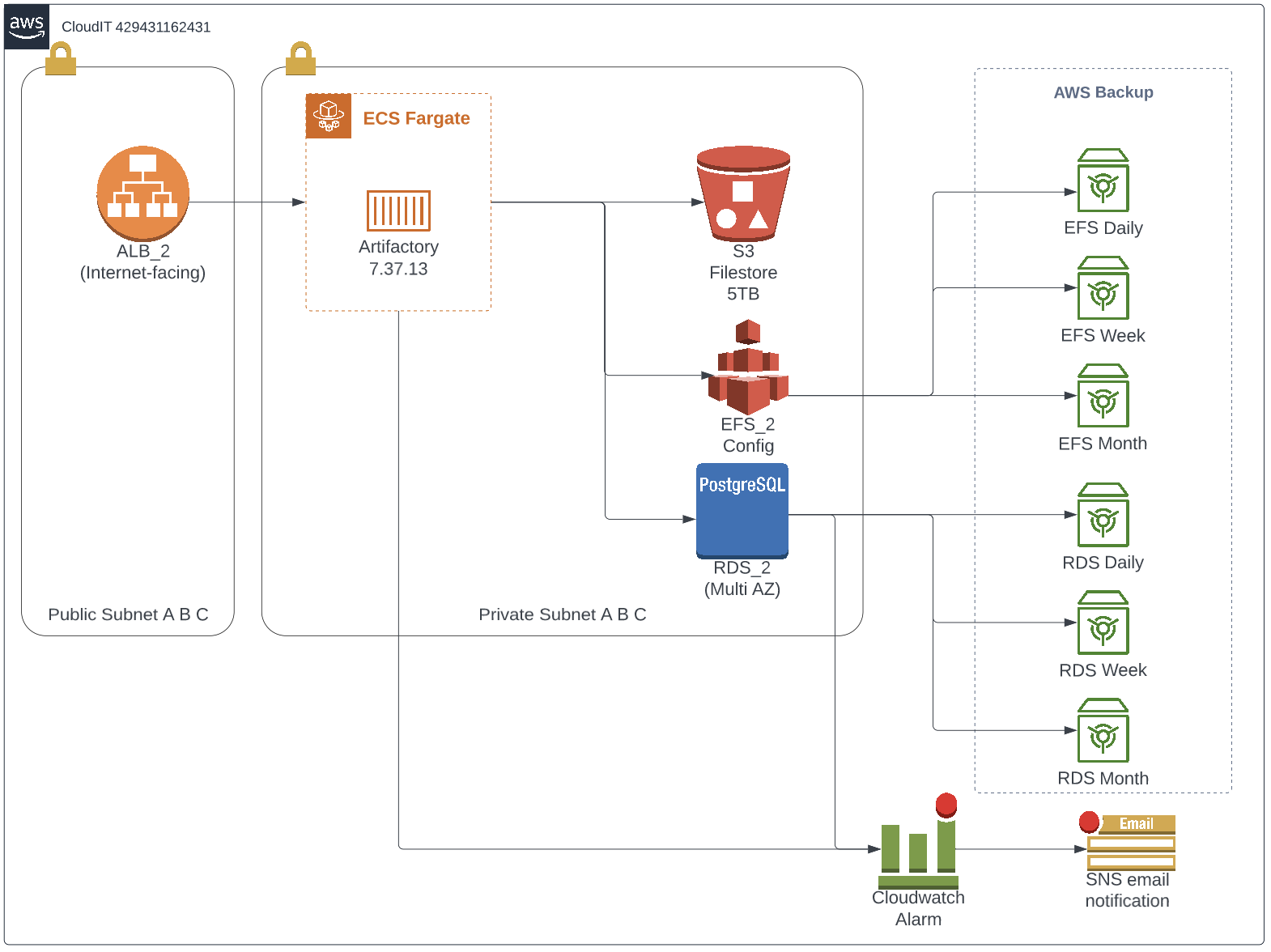
Our new Artifactory setup is much cheaper and more resilient by providing better numbers on RTO and RPO. Let’s look a the two major changes in Architecture:
- EC2 and the autoscaling group are replaced by ECS Fargate
- EFS is replaced by S3
Artifactory on ECS Fargate
Running Artifactory on ECS Fargate considerably reduces our operational overhead because Fargate
is a managed service. Using ECS, we no longer need to manage EC2 instances ourselves. It’s a pretty
straightforward container setup but remember to set up two ulimits when defining the
ECS Task Definition.
If you do not set these ulimits, the container will keep restarting and never reach a healthy state.
Ulimits:
- Name: nofile
HardLimit: 32000
SoftLimit: 32000
- Name: nproc
HardLimit: 65535
SoftLimit: 65535
EFS
In the new setup, EFS only contains the configuration files, not artifacts. The artifact storage is migrated to S3. This hugely reduces cost because EFS Artifact storage was the most expensive part of the legacy setup.
A thing to keep in mind when copying files from the old EFS to a new EFS, the ownership of files has to be updated. Artifactory has the GID 1030, which must be set on all files/folders recursively.
S3
The EFS Artifact store was replaced by S3, and the artifacts were copied using AWS DataSync. In our case, the sync took around six hours and an additional hour for Artifactory to scan the bucket afterward. Having the artifacts stored on S3 also improves our resiliency because S3 has a durability of 99.999 999 999 99% and an availability of 99.99%.
Backups
We introduced AWS Backup to create backups for RDS and EFS. For each backup policy, we created a backup vault. That way we keep a clear overview of what is stored in each vault. It’s good to know that AWS Backup only charges you for storage costs.
Monitoring
For monitoring, we have set up a few basic Cloudwatch alarms with SNS to send an email when a breach is detected.
- Trigger alarm If
HealthyHostCountlower than 1 (threshold) in 3 periods of 60 seconds (container takes on average 3 minutes to start) - Trigger alarm If
CPUUtilizationhigher than 75 percent (threshold) in 15 minutes - Trigger alarm If
FreeStorageSpacelower than 10gb
Deploying Artifactory to ECS Fargate
For a complete and detailed description check our Git repository.
Final thoughts
Everything in our new setup has been configured with RPO and RTO in mind. Either multi-AZ or global services allow us to get up and running as fast as possible.
Recovery point objectives
| Resource | Time for recovery |
|---|---|
| RDS | 30 minutes (Point in time recovery) |
| EFS | 10 minutes (Multi-AZ, should not be an issue unless the entire region or service fails) |
| S3 | 0 (S3 is highly available by default) |
| ECS | 5 minutes (If the container is unhealthy a new one will be started) |
With the new setup, we were able to reduce cost by a couple thousands of dollars a month. In the same effort, we optimized the architecture and improved the recovery objectives; the new setup allows faster recovery with less data loss.
Dead giveaway, you can spend that extra money on Articatory XRay protecting your artifacts against Supply-chain and Dependency Confusion attacks 😉